










Services on Demand
Article
 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
Indicators

Related links
-
 Cited by Google
Cited by Google -
 Similars in Google
Similars in Google
Share

 Permalink
PermalinkJournal of the Southern African Institute of Mining and Metallurgy
On-line version ISSN 2411-9717
Print version ISSN 2225-6253
J. S. Afr. Inst. Min. Metall. vol.112 n.5 Johannesburg May. 2012
TRANSACTION PAPER
Multivariate resource modelling for assessing uncertainty in mine design and mine planning
C. MontoyaI; X. EmeryI, II; E. RubioI, II; J. WiertzI
IDepartment of Mining Engineering, University of Chile, Santiago, Chile
IIAdvanced Mining Technology Centre, University of Chile, Santiago, Chile
SYNOPSIS
This paper shows, through a case study, the impact of multivariate grade modelling upon mine design and mine planning. A deposit explored by drill holes is considered, in which the grades of five elements (copper, silver, molybdenum, arsenic, and antimony) are of interest. Forty alternative models of the deposit are constructed by fitting the joint correlation structure of the grade variables and using conditional cosimulation. In addition, a reference model, obtained by averaging the alternative models, is also considered.
The study shows that the resulting mine design (final pit characteristics and production schedules) is sensitive to the grade model under consideration, and that the design based on the reference model may not be optimal when compared to the alternative models based on cosimulation. However, when assuming a given long-term plan and extraction sequence, the grades and net present value (NPV) calculated on the reference model are unbiased with respect to those calculated on the alternative models with the same extraction sequence. The latter allow assessing the possible dispersion of the actual grades and NPV around their expected values, and are useful for the planner in order to determine the probability of meeting given production targets and of exceeding or falling short of given threshold grades.
Additionally, unlike cosimulation, the separate simulation of each grade variable leads to unrealistic resource models and to biased results in mine design and mine planning. This approach should therefore be avoided, unless the grade variables are spatially uncorrelated.
Keywords: coregionalization models, cosimulation, grade uncertainty, conditional bias.
Introduction
The quantification of mineral resources, definition of mining reserves, and production scheduling are key steps of a mining project. They rely on the construction of a block model that is used to represent essentially the distribution of ore grades. However, in order to better meet the several economical, technological, and environmental constraints, block models are now designed on a more complex basis, incorporating information on the geological, geotechnical, and metallurgical attributes of interest (mineral and contaminant grades, rock density, rock type, mineralogy, alteration, grindability, recovery, floatability, solubility, etc.). Geostatistical techniques, e.g. kriging or its multivariate variant (cokriging), are often used for constructing such block models on the basis of information from logs or assays of core samples1-3.
In order to capture spatial variability and to assess spatial uncertainty, conditional simulation is becoming increasingly popular in geosciences and the minerals industry, for quantifying, classifying, and reporting mineral resources and ore reserves4-7. However, simulation is still often restricted to a single variable of interest, or to one variable at a time, while mine planning (particularly in the case of polymetallic deposits) often involves several variables with statistical and spatial dependences. This paper aims at showing how multivariate modelling and multivariate conditional simulation can improve the design and planning with respect to traditional models and can help assessing the impact of grade uncertainty on production scheduling.
Presentation of the case study
This study was performed on a porphyry copper-silver deposit located in northern Chile that will be mined by open pit. Five elements are of interest: copper (Cu) as the main product, silver (Ag) and molybdenum (Mo) as by-products, and arsenic (As) and antimony (Sb) as contaminants. Their grades have been measured in a set of exploration drill hole samples, with a proper QA/QC process in order to ensure data accuracy, and composited to a length of 6 metres. The study will focus on the sulphide zone of the orebody, insofar as the oxide zone represents less than 4 percent of the total tonnage and is not economically interesting due to low metallurgical recoveries. The samples are distributed in a volume of approximately 250 m x 600 m x 600 m.
The basic statistics of the composited data are indicated in Tables I and II. It is seen that not all the grades have been measured for all the samples, especially antimony and, to a lesser extent, molybdenum grades. Also, there exist significant correlation coefficients between copper, silver, arsenic, and antimony grades, which can be explained by the minerals associations present in the deposit (enargite, tennantite, argentotennantite, luzonite, bornite, digenite, and chalcopyrite), whereas the molybdenum grade appears to be uncorrelated with the other grades.
Resource modelling
Cosimulation of copper, silver, molybdenum, arsenic, and antimony grades
The objective of conditional simulation is to construct a set of alternative grade models (realizations) that reproduce the values at the sample locations and mimic the spatial variability of the true unknown grades at unsampled locations, as described by the grade variogram. In the multivariate case (cosimulation), it is also of interest to reproduce the spatial dependence between grades, as described by the cross variograms between grades of different attributes1,8.
In this study, cosimulation has been performed in the scope of the so-called multi-Gaussian model, which is suited to the modelling of disseminated deposits like porphyry deposits. The steps for constructing the realizations are the following1-3:
(1) Cell declustering of the original data, in order to obtain representative distributions of the grade variables
(2) Normal scores transformation of each grade variable
(3) Calculation of variogram maps of the normal scores data, in order to identify main anisotropy directions
(4) Calculation of simple and cross variograms of the normal scores data along the main anisotropy directions
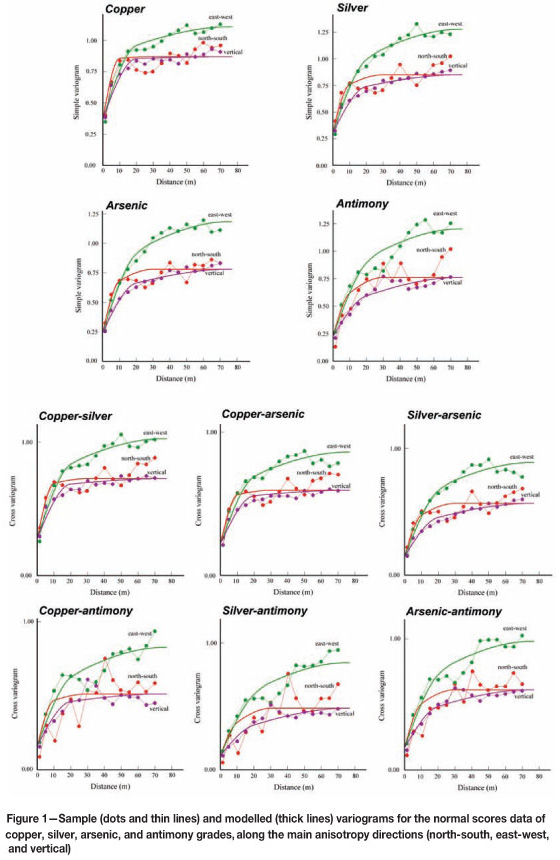
(5) Fitting of a multivariate nested model (linear model of coregionalization). The nested structures are nugget effect, spherical and exponential structures with anisotropy axes corresponding to the north-south, east-west, and vertical directions. For practicality, a semi-automated technique has been used to fit the sill matrices of each nested structure (Figure 1)9,10. According to the sample variograms and fitted models, the east-west direction turns out to exhibit less spatial continuity than the other directions. The molybdenum grade (not shown in Figure 1) has been modelled and simulated separately from the other elements, insofar as it is spatially uncorrelated with the copper, silver, arsenic, and antimony grades
(6) Non-conditional cosimulation of the Gaussian random fields with the previous coregionalization model. The turning bands method11,12 has been used at this step, and a total of forty realizations of the coregionalization have been constructed over a grid with mesh 2 m x 6 m x 6 m
(7) Conditioning to the normal scores data, via simple cokriging. Conditioning was conducted using a moving neighbourhood divided into octants, looking for six data points for each variable in each octant
(8) Back-transformation from normal scores to grade variables
(9) Checking of the cosimulation results (see next subsection)
(10) Regularization to a block support, in this case, blocks of size 4 m x 12 m x 12 m that will represent the selective mining units. The block size along the east-west direction has been chosen as the smaller because of the greater spatial variability in this direction than in the other directions. One finally obtains forty multivariate block models, each with information on the copper, silver, molybdenum, arsenic, and antimony grades. The mean copper grades of these models vary between 0.98 percent (worst case) and 1.19 percent (best case).
Checks of cosimulation results
To ensure an accurate quantification of the mineral resources and an adequate modelling of the spatial variability, it is critical that the statistics of the realizations reproduce the statistics of the grade data13. The check has been performed on the basic statistics (means, variances, and correlation matrix between variables), scatter diagrams, and simple and cross variograms of the realizations, before and after back-transformation.
As an example, Table III shows the correlation matrix between the cosimulated grade variables, which is comparable to the sample correlation matrix (Table II). Because in the present case the grades of the elements of interest are cross-correlated, the use of cosimulation is crucial to obtain realistic resources models. For instance, if the grade variables were simulated independently one from another, then the models would not reproduce the correlations between grades (Table IV).
In practice, when checking the realization statistics, one usually observes departures between the realization statistics and the data statistics. In this respect, the following points must be taken into account:
Uncertainty in model parameters - The distribution of the cosimulated grades depends on the distribution of conditioning data and on the parameters of the chosen random field model (univariate distributions fitted through normal scores transformations and simple and cross variograms fitted through a linear model of coregionalization). If these model parameters are deemed uncertain because of data scarcity or non-representativeness due to a highly irregular sampling pattern or to the presence of clustered data, alternative parameters may be heuristically proposed and used for cosimulation, leading to alternative sets of realizations. The uncertainty in the parameters can also be quantified through maximum likelihood or Bayesian approaches1,14-16. In the present study, however, no uncertainty in the model parameters has been considered, mainly because of the abundance of conditioning data (several thousands) and the well-behaved sample variograms that allow a good-quality fitting of a coregionalization model (Figure 1)
Statistical fluctuations are smaller when the simulation domain is larger. In practice, to judge whether or not the domain is large, one may compare the domain size with the range of correlation or with the integral range of the random fields under studyu8. In the present case, the domain measures 260 m x 588 m x 588 m, whereas the ranges of the basic nested structures used in the coregionalization model are no more than 75 m (Figure 1).

Another consideration in choosing the number of realizations is to calculate the probability that a given output of interest (for instance, the mean copper grade) is outside the range of the outputs calculated on the realizations. Assuming that one has n realizations homologous to the real deposit, the probability that the real output value is greater than the n simulation outputs is 1 out of n+1, the probability that it is smaller than the n simulation outputs is 1 out of n+1, and the probability that it is in between the n simulation outputs is therefore 1 - 2/(n + 1) = (n - 1)/(n + 1). Accordingly, with n = 10 realizations, one obtains an 81.8 percent confidence interval on the real output, whereas with n = 40 realizations, as this is the case here, one obtains a 95.1 percent confidence interval.
Average of the realizations
Mine planning is usually undertaken with a single grade model instead of multiple realizations. In practice, this model may be obtained by averaging the realizations or by directly interpolating the grade data via inverse distance weighting, kriging or cokriging3.
In this context, the average of the forty realizations has been calculated for each element of interest, which yields a block model with the 'expected' grades, in the sense that it approximates the expectation of the true unknown grades conditioned to the available grade data. Such a block model smoothes the actual grade variability and is comparable to that obtained by cokriging. For instance, before block-support regularization, the copper grade variance varies between 1.20 and 1.90 for the individual realizations, but decreases to 0.19 for the average of realizations.
As an illustration, maps of the copper grade distribution at a specific elevation are presented in Figure 3, for the original sample data, two realizations, the average of realizations, and the cokriging estimates. The correlation coefficient between the last two block models (average of realizations and cokriging) is 0.81, indicating that both models yield similar values. The differences can be explained because of the finite number of realizations and because cosimulation works with non-linearly transformed variables (normal scores data), whereas cokriging works directly with the original grade variables: if the transformation functions are highly non-linear, which happens when the grade distributions are heavy-tailed, the average of realizations may deviate from the cokriging estimates1,3.

Despite its smoothness, an interesting property of the block model obtained by averaging the realizations is the lack of conditional bias: the regression of the true (unknown) grades upon the grades given by the block model is the identity function1,19,20. This property will help to explain some of the results presented in the following sections (see also Appendix). In general, conditional unbiasedness also holds for the cokriging block model, provided that the cokriging neighbourhood has been adequately defined19,21.
Mine design and planning using multiple block models
For a given resource model and given economic and technical conditions, the design step consists of defining the final pit as well as the limits of the different extraction phases, which define the sequence for mining the orebody. This step has been carried out by applying the approach proposed by Whittle that uses the well-known max-flow algorithm presented by Lersch and Grossmann22-23, with the parameters indicated in Table V and without considering the definition of roads and accesses (unsmoothed pit). The blocks located above the surface topography and outside the resource models obtained by cosimulation have been assigned grades equal to zero.
In this section, it is of interest to determine the differences in design and production scheduling between the previously defined resources models (each individual realization, and the average of realizations).
Determination of final pits and production schedules
For the resource model corresponding to the expected grades (average of forty realizations), a preliminary analysis considering only the main product (copper) shows that the production rate maximizing the net present value (NPV) is 54.92 kt/day of ore sent to mill, associated with a cut-off copper grade of 0.6 percent. For such a cut-off, one obtains an economic shell with 197.73 Mt of ore at an average copper grade of 1.13 percent and 18.84 Mt of waste, with a mine lifetime of 10 years.
According to these results and after trial and error, the final production rate has been set to 55 kt/day, the mill capacity to 20.08 Mt/a, the ratio between waste and ore to 2, the mine capacity to 45.17 Mt/a for the first year and 60.23 Mt/a for the following years. The production schedules are then valued by considering copper, silver, and molybdenum as attributes with an economic interest.
The final open pit is found to be the one associated with a revenue factor (copper recovery multiplied by the difference between copper price and smelting cost) equal to 0.74 (pit no. 40 in Figure 4). It was decided to divide the pit into four phases of approximately the same size. In this case, the production scheduling yields a NPV of US$1 207 million (considering mine and mill investments).

The same design process is finally applied to each of the forty realizations, choosing the same production rate and ore/waste ratio.
Comparison of block models
The final pits and production schedules so obtained are compared on the basis of the mineral resources (ore and waste tonnages, average grades) (Table VI) and NPV (Table VII) for three block models: the average of realizations, and two single realizations corresponding to the best and worst scenarios in terms of average copper (main product) grade for the overall block model.

It is seen that the characteristics of the final pit are likely to be very different, depending on which block model is considered (a single realization or the average of forty realizations): grades are substantially higher in the case of individual realizations, but ore tonnages are smaller. Such differences have a considerable impact on the NPV and the profitability of the project. This can be explained because of the smoothing effect produced by averaging the realizations: the amount of intermediate-grade material increases, entailing a higher ore tonnage above cut-off (low grades are scarcer) with lower average grades (high grades are scarcer).
The realizations show that the NPV can vary between US$1 027 million and US$1 538 million. As each realization is equiprobable and homologous to the true deposit, this indicates that the actual NPV may vary in between these two bounds (with 95 percent probability, as per the previous discussion on the number of realizations). Thus, by assuming a production schedule based on the average of the realizations, the calculated NPV (US$1 207 million) may be overestimated by up to US$180 million or underestimated up to US$331 million with respect to a production schedule based on a single realization. These values represent the financial uncertainty of the mining project due to grade uncertainty.
Comparison with block models obtained by separate grade simulation
It is also interesting to compare the results with those associated with the block models obtained by separately simulating each grade variable. It is observed (Tables VIII and IX) that, with such models, ore tonnages are strongly underestimated, grades are overestimated, and NPVs are overestimated. Because the block models do not reproduce spatial correlations between grades, all these results are biased and give the misleading impression that the deposit is economically more attractive than in reality. This exercise shows the importance of jointly considering and modelling all the variables of interest, when these variables are cross-correlated, in order to avoid conditional biases (Appendix).
Uncertainty associated with a given schedule
Methodology
To characterize the variability that could be observed during mine operations, following a given long-term plan, we will assess the variations in the extracted tonnages and grades by applying this plan to some of the realizations, each of which represents a plausible scenario of the real deposit. The steps are the following (Figure 5):

(1) We use the block model corresponding to the expected grades (average of forty multivariate realizations) in order to calculate the final pit and production schedule, by considering the main product (copper), by-product (silver, molybdenum) and contaminant (arsenic, antimony) grades for valuing the plan. From this, we obtain an extraction sequence that will be considered as the reference case used in the actual mine operations (Figure 6)
(2) This extraction sequence is applied successively to ten realizations chosen at random among the forty available realizations, in order to assess the probability that the results predicted in the previous step can be met in the actual operations. As a consequence of this process, we find different production schedules in which the ore and waste tonnages are the same, but the grades vary, so that the NPV also varies from realization to realization.

Uncertainty in grades
The grades associated with each production schedule are presented in Figure 7.

For each variable, the grade values associated with the reference case (average of forty realizations) almost exactly coincide with the average of the grade values associated with each individual realization. This indicates that, although it relies on a smoothed grade model, the reference case allows predicting accurately (i.e. without any systematic bias) the grades that are expected to be extracted. This is a consequence of the conditional unbiasedness property of the average of realizations: the recovered resources (tonnages, mean grades, metal contents) are accurately predicted with a conditionally unbiased grade model1,19,20.
Additionally, the use of multiple realizations allows determining the range of possible results around those obtained in the reference case, as well as the probability that the actual (unknown) grades are more or less than the predicted grades for a given period of time, i.e. the probability that the production targets can be accomplished. For instance, in the case of arsenic and antimony, it is found that three of the ten realizations exceed the value predicted in the reference case for the first year, meaning that there is about a 30 percent risk of finding greater arsenic and antimony grades than initially planned. This analysis is all the more relevant if one considers restrictions on arsenic grades, insofar that it is not sufficient that the restrictions are fulfilled in the reference case: they should also be fulfilled in most of the realizations in order to minimize the risks of not meeting the planned targets. In particular, high arsenic and antimony grades may have a negative impact on the concentrate quality and on the recovery process in the concentrator, and also on the smelting process, in which a fraction of the input arsenic and antimony is emitted to the atmosphere. Most copper smelters apply severe restriction on the arsenic content of the concentrates that they accept for processing, therefore the mine planning should integrate this additional restriction to the production schedule.
Ideally, although it is time-consuming, one should apply the production schedule to a larger number of realizations. This would help to better determine by how much extracted grades may fluctuate around the reference case estimates, and to better assess the probability of finding grades lower or greater than given thresholds.
Uncertainty in net present value
The realizations also allow determining the financial risk associated with the planned sequence (Table X). Again, it is seen that, although the variation in the NPV can reach 20.1 percent of the initially planned value, the NPV calculated in the reference case is very close to the average of the NPVs calculated in each realization. This is again explained by the conditional unbiasedness property of the reference case model and because the NPV is a linear function of the grades (given a fixed mining sequence and fixed economic and technical parameters).

So far, conditional unbiasedness has been recognized as an important property for short-term planning and grade control, but there is still some controversy about its usefulness in long-term planning24. Here, we show that conditional unbiasedness is of interest for long-term planning in order to accurately predict the expected NPV of the mining project. Note that this result may not hold any more, and one may therefore have a bias between the NPV calculated in the reference case with respect to the NPVs calculated on individual realizations, if25,26:
Conclusions
Geostatistical cosimulation allows constructing models of multiple grade variables (or of other geological or metallurgical variables) that reproduce the spatial variability and spatial dependence of the true grades, as well as the information available at sample locations (drill hole data). In contrast, the model obtained by averaging the realizations yields a smoothed image of the real deposit, although it is conditionally unbiased, whereas models obtained by simulating the grade variables separately do not reproduce the spatial dependences between the variables. The latter provide biased results in mine design and planning and should therefore be avoided, excepted when the grade variables do not have any spatial cross-correlation.
When applying given criteria and planning parameters to the block models obtained by cosimulation and to the average of the realizations, considerable differences are found in the final pit characteristics and net present values of the production schedules. The optimal planning for one model is likely not to be optimal for another model. To date, planning is often performed on a smooth block model obtained by kriging or by averaging realizations, so that it may not be optimal. The question of determining the best plan accounting for grade uncertainty still remains open25.
However, assuming the extraction sequence obtained on the average of realizations as a reference case, it is observed that this sequence applied to each realization yields grade values and NPVs that fluctuate around those obtained in the reference case, without a systematic bias. This is explained because the reference case model is conditionally unbiased, a condition that should be checked when constructing grade models by kriging, cokriging, or any other method21. Furthermore, because the realizations are equiprobable, they allow assessing the uncertainty in grades for each production period, or in NPV for the whole project, and calculating the probability of not fulfilling a given target or exceeding a given environmental norm. This information is helpful to investors in order to quantify how grade uncertainty could impact the technical and economical results of the mining project.
The ability to take account of the grade uncertainty should be seen as a business opportunity. It should be supported by a long-term plan that does not necessarily maximize NPV, but maximizes the probability of meeting the best possible NPV. Also, considering several variables (geological, environmental, geotechnical, and metallurgical attributes, which, in general, are cross-correlated) gives a holistic vision of the mining operations from the orebody evaluation to downstream processing. One of the main challenges would then be the weighting of these variables in the optimization process for mine design and mine planning.
Acknowledgements
This research was funded by the Chilean Commission for Science and Technology Research (CONICYT), through FONDEF project D04I1055 and FONDECYT project 1090013. The authors are grateful to an anonymous reviewer for his/her comments on a former version of the manuscript.
Appendix: Conditional unbiasedness
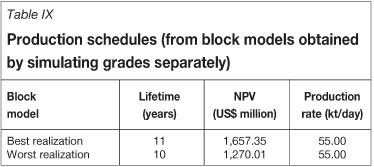
For a given block (v) in the deposit, let  (v) be the vector of actual grades (in the present case study, a vector with five components, corresponding to copper, silver, molybdenum, arsenic, and antimony grades) and
(v) be the vector of actual grades (in the present case study, a vector with five components, corresponding to copper, silver, molybdenum, arsenic, and antimony grades) and  (v) the vector of estimated grades obtained by averaging the cosimulation models conditioned to the sample data available in and around the block under consideration (located at x1... xn). Such a vector of estimated grades can be identified with the conditional expectation of the actual grades, that is, the expected values of the actual grades given the data grades:
(v) the vector of estimated grades obtained by averaging the cosimulation models conditioned to the sample data available in and around the block under consideration (located at x1... xn). Such a vector of estimated grades can be identified with the conditional expectation of the actual grades, that is, the expected values of the actual grades given the data grades:

The conditioning data (x1)... (xn) appear to be summarized, without loss of information, by the estimator Z (v), which means that the knowledge of the former is equivalent to the knowledge of the latter. Accordingly, one can write:1,14
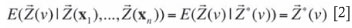
Equation [2] corresponds to the conditional unbiasedness property: given the vector of estimated grades, the expected vector of actual grades is equal to the estimated grades. From this property, any quantity that is expressed linearly as a function of the grades is predicted accurately (without systematic bias) from the same quantity calculated on the estimated grades (average of cosimulated grades). This is the case of the recoverable resources - grades and metal contents - and NPV associated with a given mining plan and extraction sequence.
Conditional unbiasedness does not necessarily hold if one simulates the grades separately (univariate modelling approach) instead of cosimulating them. Indeed, let  (v) be the vector obtained by averaging the grades simulated separately. The components of this vector are (indexes 1 to 5 refer to copper, silver, molybdenum, arsenic and antimony):
(v) be the vector obtained by averaging the grades simulated separately. The components of this vector are (indexes 1 to 5 refer to copper, silver, molybdenum, arsenic and antimony):
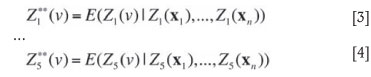
Considering copper grades alone, the estimator is conditionally unbiased:

However, because the components of (v) are cross-correlated, the knowledge of Zi** (v),...,Z5** (v) is likely to affect the expected value of Z1(v) with respect to the knowledge of Z1**(v) only:

The same arguments can be applied to the other components of (v), so that one finally has:
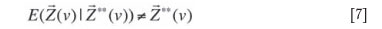
Accordingly, even if they are expressed linearly as a function of the grades, quantities such as metal contents, mean grades, and NPVs are no longer predicted accurately from the same quantities calculated on the estimated grades (average of separately simulated grades), and biases may be observed. Two noteworthy exceptions to this rule are:
(1) the case when the components of
(2) the case when these components are informed at all the data locations and their simple and cross variograms are proportional.
In these two cases, the average of simulation models coincide with the average of cosimulation models27-29. Now, the present study does not correspond to any of these two exception cases, insofar as the grades are cross-correlated (Table II), they are not known at all the data locations (Table I) and their variograms are not proportional, for instance the copper grade variogram has a higher relative nugget effect than the other variograms (Figure 1).
References
1. CHILÉS, J.P. and DELFINER, P. Geostatistics: Modeling Spatial Uncertainty. New York, Wiley, 1999. pp. 695. [ Links ]
2. DEUTSCH, C.V., and JOURNEL, A.G. GSLIB: Geostatistical Software Library and User's Guide, 2nd edn. New York, Oxford University Press, 1998. pp. 369. [ Links ]
3. JOURNEL, A.G., and HUIJBREGTS, C.J. Mining Geostatistics. London, Academic Press, 1978. pp. 600. [ Links ]
4. JOURNEL, A.G. Geostatistics for conditional simulation of orebodies. Economic Geology, vol. 69, no. 5, 1974. pp. 673-687. [ Links ]
5. JOURNEL, A.G., and KYRIAKIDIS, P.C. Evaluation of mineral reserves: a simulation approach. Oxford, Oxford University Press, 2004. pp. 216. [ Links ]
6. DOHM, C.E. Applications of simulation techniques for combined risk assessment of both geological and grade models - an example. 31st International Symposium on Computer Applications in the Minerals Industry APCOM, Cape Town, Johannesburg, 14-16 May 2003. The South African Institute of Mining and Metallurgy, 2003. pp. 351-354. [ Links ]
7. SNOWDEN, D.V. Practical Interpretation of Mineral Resources and Ore Reserve Classification Guidelines. Mineral Resource and Ore Reserve Estimation - the AusIMM Guide to Good Practice. Edwards, A.C. (ed.). Melbourne. The Australasian Institute of Mining and Metallurgy, 2001. pp. 643-653. [ Links ]
8. WACKERNAGEL, H. Multivariate Geostatistics: An Introduction with Applications, 3rd edn. Berlin, Springer, 2003. pp. 387. [ Links ]
9. GOULARD, M. and VOLTZ, M. Linear coregionalization model: tools for estimation and choice of cross-variogram matrix. Mathematical Geology, vol. 24, no. 3, 1992. pp. 269-286. [ Links ]
10. EMERY, X. Iterative algorithms for fitting a linear model of coregionalization. Computers & Geosciences, vol. 36, no. 9, 2010. pp. 1150-1160. [ Links ]
11. EMERY, X. and LantuSjoul, C. TBSIM: a computer program for conditional simulation of three-dimensional Gaussian random fields via the turning bands method. Computers & Geosciences, vol. 32, no. 10, 2006. pp. 1615-1628. [ Links ]
12. EMERY, X. A turning bands program for conditional cosimulation of cross-correlated Gaussian random fields. Computers & Geosciences, vol. 34, no. 12, 2008. pp. 1850-1862. [ Links ]
13. LEUANGTHONG, O., MCLENNAN, J.A., and DEUTSCH, C.V. Minimum acceptance criteria for geostatistical realizations. Natural Resources Research, vol. 13, no. 3, 2004. pp. 131-141. [ Links ]
14. DUBRULE, O. Estimating or choosing a geostatistical model? Geostatistics for the Next Century. Dimitrakopoulos, R. (ed.). Dordrecht. Kluwer Academic, 1994. pp. 3-14. [ Links ]
15. PARDO-IGUZQUIZA, E. Bayesian inference of spatial covariance parameters. Mathematical Geology, vol. 31, no. 1, 1999. pp. 47-65. [ Links ]
16. DOWD, P.A. and PARDO-IGUZQUIZA, E. The incorporation of model uncertainty in geostatistical simulation. Geographical and Environmental Modelling, vol. 6, no. 2, 2002. pp. 147-169. [ Links ]
17. EMERY, X. Statistical tests for validating geostatistical simulation algorithms. Computers & Geosciences, vol. 34, no. 11, 2008. pp. 1610-1620. [ Links ]
18. LANTUEJOUL, C. Ergodicity and integral range. Journal of Microscopy, vol. 161, no. 3, 1991. pp. 387-403. [ Links ]
19. KRIGE, D.G. A practical analysis of the effects of spatial structure and of data available and accessed, on conditional biases in ordinary kriging. Geostatistics Wollongong '96. Baafi, E.Y., and Schofield, N.A. (eds.). Dordrecht, Kluwer Academic, 1997. pp. 799-810. [ Links ]
20. MATHERON, G. The selectivity of the distributions and the second principle of geostatistics. Geostatistics for Natural Resources Characterization. Verly, G., David, M., Journel, A.G., and Marechal, A. (eds.). Dordrecht, Reidel, 1984. pp. 421-433. [ Links ]
21. VANN, J., JACKSON, S., and BERTOLI, O. Quantitative kriging neighbourhood analysis for the mining geologist - a description of the method with worked case examples. 5th International Mining Geology Conference, Melbourne. The Australasian Institute of Mining and Metallurgy, 2003. pp. 215-223. [ Links ]
22. LERCHS, H. and GROSSMANN, I.F. Optimum design of open-pit mines. CIM Bulletin, vol. 58, 1965. pp. 17-24. [ Links ]
23. WHITTLE, J. Open Pit Optimization, Surface Mining, 2nd edn. AME, 1990. pp. 470-475. [ Links ]
24. ISAAKS, E. The kriging oxymoron: a conditionally unbiased and accurate predictor. (2nd edn). Geostatistics Banff2004. Leuangthong, O., and Deutsch, C.V. (eds.). Dordrecht. Springer, 2005. pp. 363-374. [ Links ]
25. DIMITRAKOPOULOS, R., FARRELLY, C.T., and GODOY, M.Moving forward from traditional optimization: grade uncertainty and risk effects in open-pit design. Transactions of the Institute of Materials, Minerals and Mining. Section A: Mining Technology, vol. 111, no. 1, 2002. pp. 82--88. [ Links ]
26. NICHOLAS, G.D., COWARD, S.J, and FERREIRA, J. Financial risk assessment using conditional simulation in an integrated evaluation model. Eighth International Geostatistics Congress Geostats2008. Ortiz, J.M. and Emery, X. (eds.). Santiago. Gecamin Ltda, 2008. Pp.759-768. [ Links ]
27. RIVOIRARD, J. On some simplifications of cokriging neighborhood. Mathematical Geology, vol. 36, no. 8, 2004. pp. 899-915. [ Links ]
28. SUBRAMANYAM, A. and PANDALAI, H.S. On the equivalence of the cokriging and kriging systems. Mathematical Geology, vol. 36, no. 4, 2004. pp. 507-523. [ Links ]
29. SUBRAMANYAM, A. and PANDALAI, H.S. Data configurations and the cokriging system: simplification by screen effects. Mathematical Geosciences, vol. 40, no. 4, 2008. pp. 425-443. [ Links ]
Paper received Sep. 2011; revised paper received Nov. 2011.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}